
Elasticsearch 7.x 入门与实践

前言
我们建立一个网站或者应用程序,经常用到搜索功能,我们自己实现复杂的搜索且性能强大、高可用、运行速度快是非常困难的,Elasticsearch 很好地帮助我们解决了这个问题。
百度百科:https://baike.baidu.com/item/elasticsearch/3411206?fr=aladdin
官网地址:https://www.elastic.co/cn/products/elasticsearch
Github:https://github.com/elastic/elasticsearch
ES 优点
- 可以实时地去索引、搜索数据。
- 扩展性好,可部署上百台服务器做集群,处理 PB 级数据。
ES 原理、应用
索引结构
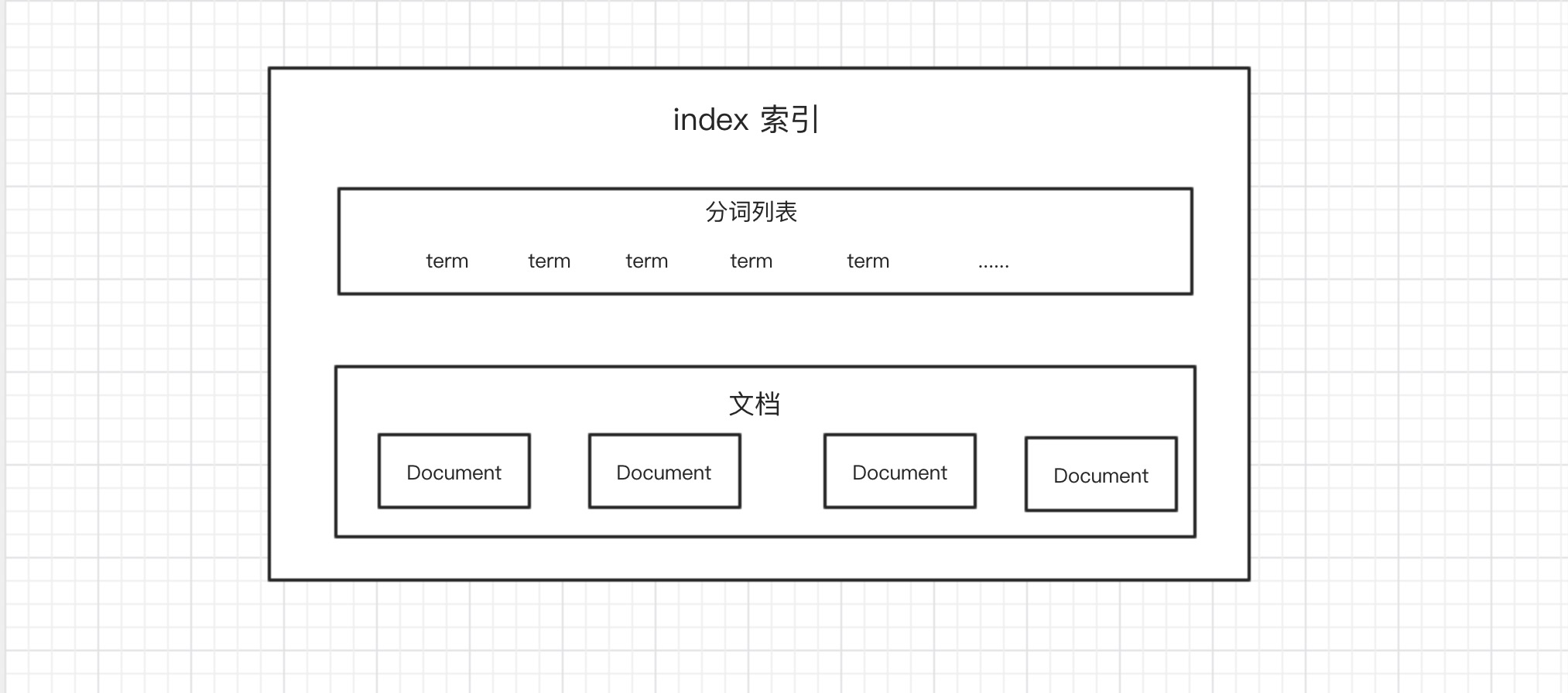
ES 的索引是倒排索引表,ES 将要被搜索的数据根据指定的分词器进行分词,这些数据在 ES 中以文档存储,并将这些分词与文档进行关联。
Restful
ES 通过提供 restful api 供客户端使用
ES 文件目录结构
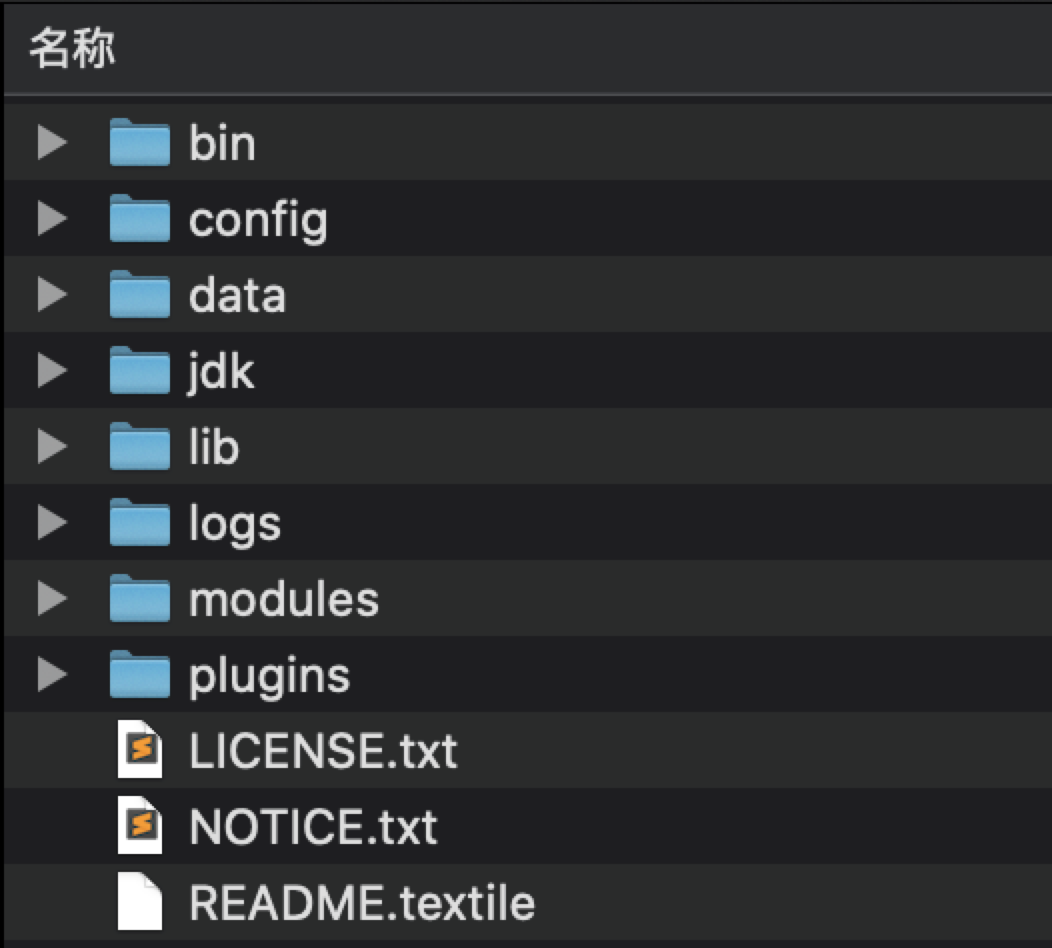
bin::可执行文件
config:配置文件
jvm.options:配置 es 的 jvm 参数,一般将 xms 和 xmn设置为
log4j2.properties:es 使用 log4j2 打印日志
elasticsearch.yml:es 核心配置文件
data:数据
logs:日志
modules:es模块目录
plugins:es 插件比如 ik 分词器
elasticsearch.yml 常用配置
cluster.name: es 集群的名称 默认是 elasticsearch ,建议修改为与项目相关的名称。
node.name: 此 es 节点名称,通常一个 es 应用就是一个节点,建议指定。
node.master: 指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新
的master。
node.data: 指定该节点是否存储索引数据,默认为true。
path.data: 索引数据的存储路径。
path.logs: 日志文件的存储路径。
bootstrap.memory_lock: true 设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。
network.host: 设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体 的ip。
http.port: 9200 设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300 集群结点之间通信端口。
http.cors.enabled: true
http.cors.allow-origin: “*” 允许跨域。discovery.zen.ping.timeout: 3s 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。
discovery.zen.minimum_master_nodes:为了防止数据丢失,这个 配置在 7.x 版本之前至关重要, 以便每个候选主节点知道为了形成集群而必须可见的最少数量的候选主节点。没有这种设置,遇到网络故障的群集有可能将群集分成两个独立的群集(脑裂), 这将导致数据丢失。为了避免脑裂,候选主节点的数量应该设置为:
换句话说,如果现在有3个节点,最小候选主节点数应该是(3/2)+1=2。
注意:在 Elasticsearch 7.x 中,重新设计并重建了集群协调子系统:移除了 minimum_master_nodes 设置,让 Elasticsearch 自己选择可以形成法定数量的节点。
- 好处1:用户无需设置最小主节点个数了,集群层面给解决了。
- 好处2:避免用户配置错误导致出现脑裂问题。
- 好处3:选主更快了。
虽然在 7.x 版本中不用配置此参数,但也需要了解一下其原理。
系统配置
ES 部署到 Linux 服务器上,一般需要将每个进程最多允许打开的文件数设置的大一些。
1 | ulimit -n // 查看当前最大文件打开数 |
/etc/security/limits.conf 文件中加入
1 | elasticsearch ‐ nofile 65535 |
表示 为 elasticsearch 用户设置最大文件打开数为 65535
入门
Ik 分词器
ES 中我们经常使用的中文分词器是 ik 分词器
Github: https://github.com/medcl/elasticsearch-analysis-ik
下载与 es 版本对应的 ik分词器,将其解压后放置 es 的 plugins目录下,并命名为 ik
ik分词器还支持自定义词库。
创建索引
ES 索引(index)是个逻辑概念,包括了分词列表和文档,相当于 mysql 中的表
ES 的文档可以理解为 mysql 表中的每一行数据
ES 的字段可以理解为 mysql 表中的每列字段
示例:使用 head 插件创建索引
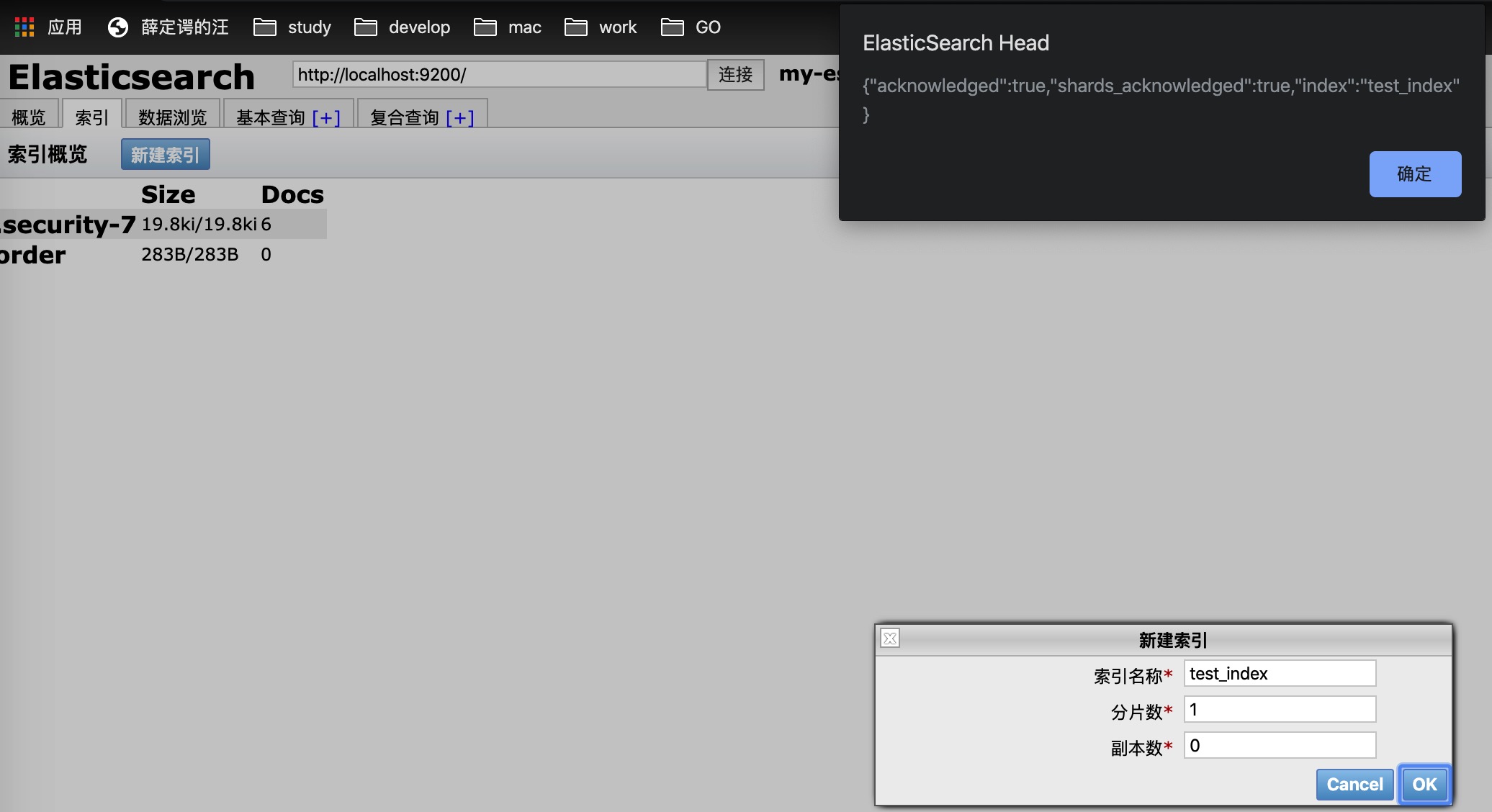
单机情况下,数据分片为 1,副本数为 0 即可。
创建映射
一个索引中的文档包括多个字段,创建映射就是为索引创建字段的过程,
注意:ES 在6.0之前版本中 type 的概念,但是之后不使用了,ES 官方计划将于 9.0版本中彻底删除 type。
head 插件中发送 post 请求创建 mapping
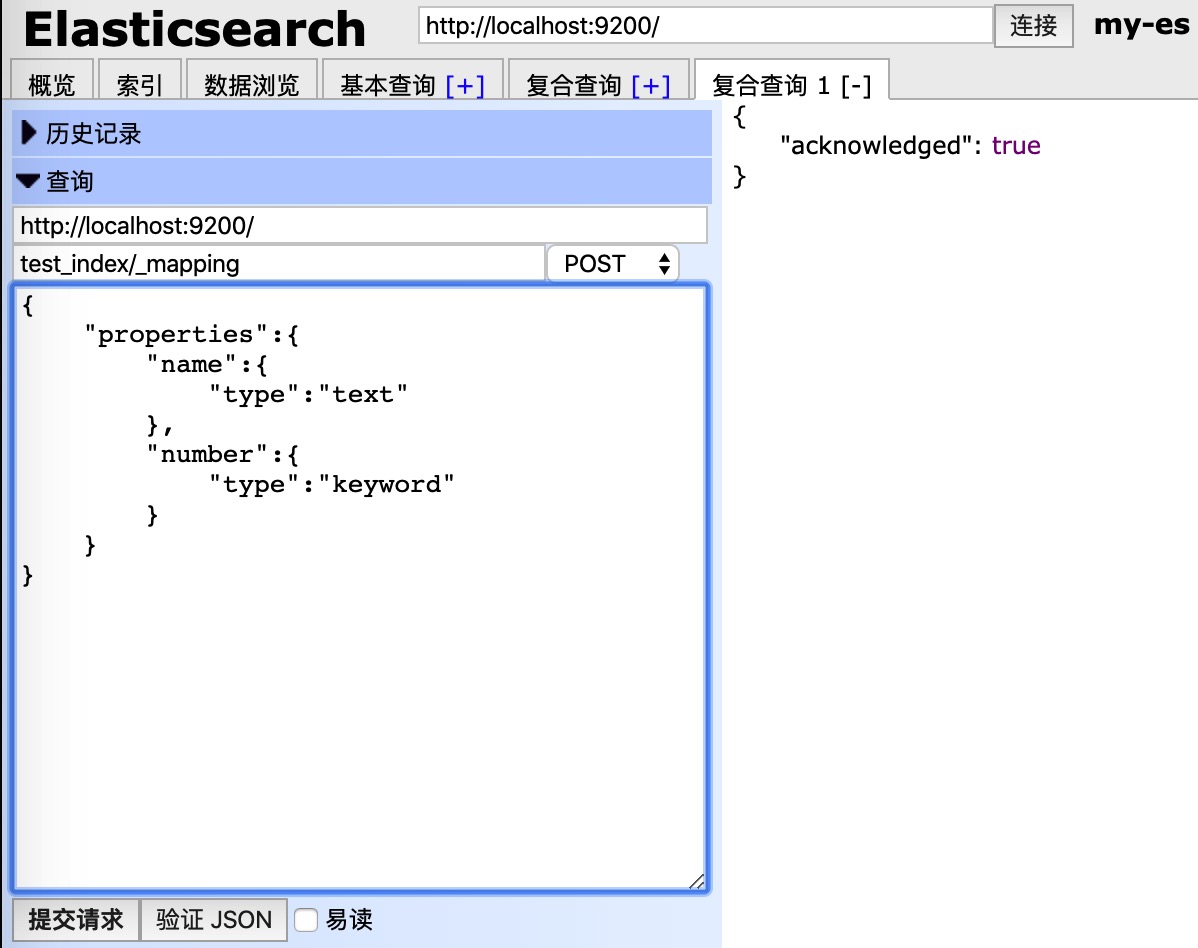
1 | { |
查看映射
发送 get 请求即可
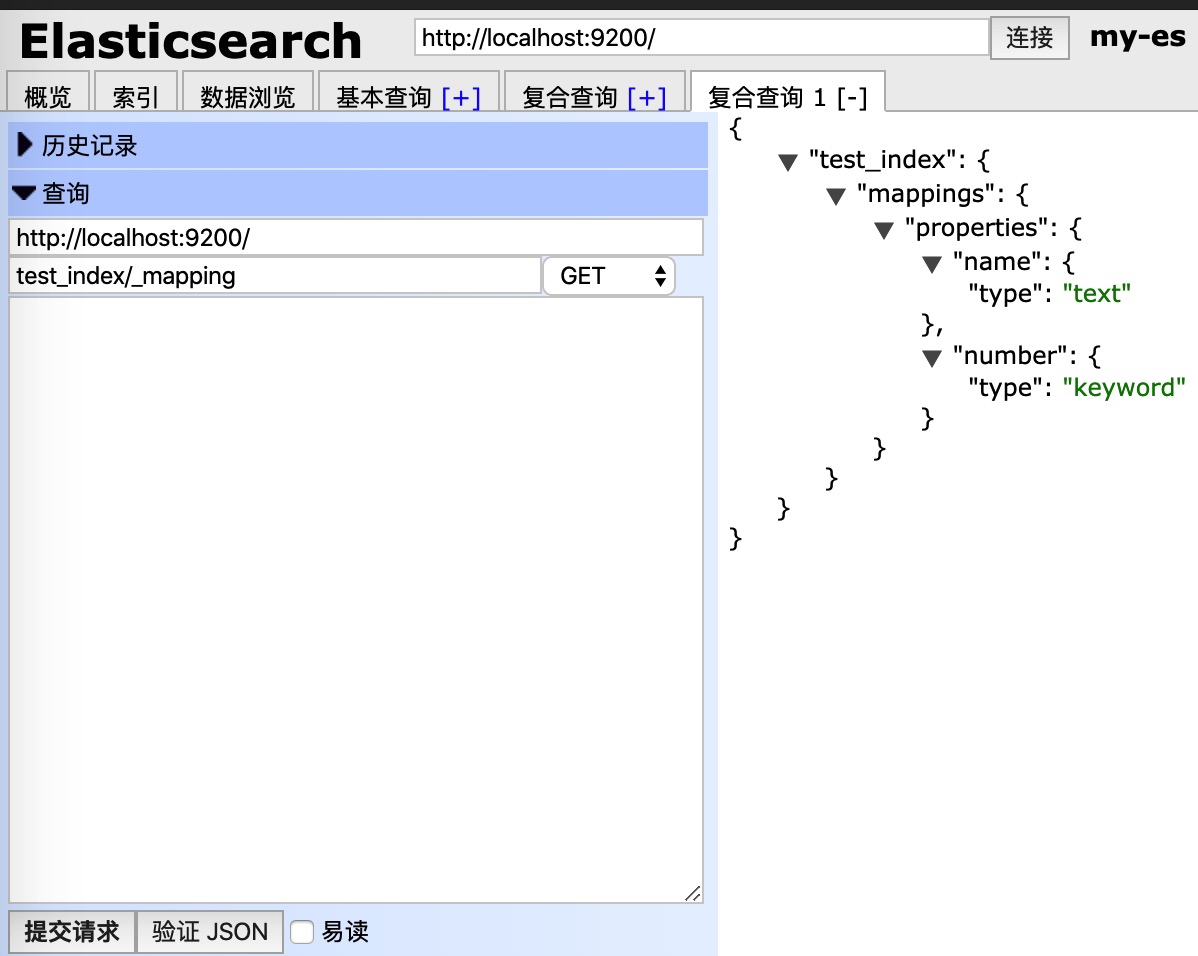
更新映射
映射创建成后,可以添加新字段,已有的字段不允许更新,如果非要更新则需要重新创建索引、映射。
删除映射
通过删除索引来删除映射
映射类型
文本类型 text 和 keyword
text: 内容会被分词,不能用于排序
analyzer:指定分词器 如:ik_max_word
search_analyzer:单独指定搜索时的分词器
ik中文分词最佳实践:索引时使用ik_max_word将搜索内容进行细粒度分词,搜索时使用ik_smart提高搜索精确性。
2
3
4
5
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}keyword: 内容不会被分词
text 和 keyword 都可以通过index属性指定是否索引:
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。
但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置 为false。
store:
是否在source之外存储,默认 false,每个文档索引后会在 ES中保存一份原始文档,存放在”_source”中,一般情况下不需要设置 store为 true,因为在 _source 中已经有一份原始文档了。
数字类型
数字类型有如下分类:
| 类型 | 说明 |
|---|---|
| byte | 有符号的8位整数, 范围: [-128 ~ 127] |
| short | 有符号的16位整数, 范围: [-32768 ~ 32767] |
| integer | 有符号的32位整数, 范围: [$-2^{31}$ ~ $2^{31}$-1] |
| long | 有符号的32位整数, 范围: [$-2^{63}$ ~ $2^{63}$-1] |
| float | 32位单精度浮点数 |
| double | 64位双精度浮点数 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数, 比如price字段只需精确到分, 57.34缩放因子为100, 存储结果为5734 |
使用注意事项:
尽可能选择范围小的数据类型, 字段的长度越短, 索引和搜索的效率越高;
日期类型 date
日期类型不用设置分词器,通常日期类型的字段用于排序。
可以用 format 来指定日期格式:
1 | "createTime":{ |
表示该日期支持 年月日时分秒 、年月日和时间戳三种格式。
创建文档
使用 put 或 post 请求为索引创建文档,如果不指定 id,es 会默认创建
实战
ES 客户端
TransportClient:ES提供的传统客户端,官方计划8.0版本删除此客户端。
RestClient:
RestClient是官方推荐使用的,它包括两种:Java Low Level REST Client和 Java High Level REST Client。
ES在6.0之后提供 Java High Level REST Client, 两种客户端官方更推荐使用 Java High Level REST Client,不过当 前它还处于完善中,有些功能还没有,在我们的项目中使用足够了。
注:spring 虽然已经集成了es spring-data-elasticsearch,并提供了一些常用的操作 ES 的 api,但考虑到我们搜索业务的复杂性,最终选用更灵活,更适合我们的 es 官网提供的客户端。
maven 依赖
以 7.3.2 版本为例:
1 | <dependency> |
代码示例
用的是 springboot 构建的项目,yml 配置文件中添加
1 | elasticsearch: |
配置类:
1 |
|
准备数据
创建 book 索引和对应 mapping:
post http://localhost:9200/book/_mapping
1 | { |
向 book 索引插入文档:
1 |
|
准备多条数据供查询使用
ES 搜索 API
查询所有文档
1 |
|
分页查询
ES 分页查询传入两个参数 from 和 size
from: 表示起始文档的下表,从 0 开始。
size: 查询的文档数量
在项目中,分页时经常传入两个参数,pageNum(当前页)和 pageSize(每页数量)
在 ES 中的对应关系:
from = (pageNum - 1) * pageSize;
size = pageSize;
java 代码:
1 |
|
关于 ES 深分页问题
查询 ES 每次查询命中数据量不大的情况下,from&size 这种方式即可满足要求,比如我们用户在查询订单时每页就显示 10 条,每个用户的订单量也不是很多,用 from&size 足够了。
如果每次查询命中的数据量大的话,from&size 这种方式查询的分页越深,性能越差,比如当 from=10000,size = 100,这这时候就需要从每个分片上查询出 10100 条数据,然后汇总计算出前 100 条,分片数越多查询压力越大。
ES 为了避免深分页,不允许使用分页(from&size)查询10000(index.max_result_window:10000)条以后的数据,这时可以用 scroll 游标方式来查询,具体看业务需求。
Term Query
Term Query为精确查询,在搜索时会整体匹配关键字,不再将关键字分词。
1 |
|
根据 id 精确匹配
1 | `List<String> ids = Lists.newArrayList("Hv6rqm4B068QQUwT7fJl", "H_6_qm4B068QQUwT9PK9"); |
match query
match Query即全文检索,它的搜索方式是先将搜索字符串分词,再使用各各词条从索引中搜索。
match query与Term query区别是match query在搜索前先将搜索关键字分词,再拿各各词语去索引中搜索。
1 | searchSourceBuilder.query(QueryBuilders.matchQuery("desc", "深入理解").operator(Operator.OR)); |
operator 设置为 or 表示搜索关键字分词后只要有一个词匹配成功就返回该文档。
operator 设置为 and 表示所有分词都匹配成功才返回。
minimum_should_match:
上边使用的operator = or表示只要有一个词匹配上就得分,如果实现三个分词至少有两个词匹配如何实现?
使用minimum_should_match可以指定文档匹配词的占比:
1 | searchSourceBuilder.query(QueryBuilders.matchQuery("desc", "深入理解虚拟机").minimumShouldMatch("80%")); |
“深入理解虚拟机” 可能被分为三个词:深入、理解、虚拟机,minimum_should_match = 80% 表示 3*0.8 = 2.4,取整为 2,表示这三个词中至少要有两个词匹配才返回文档。
multi Query
multi Query 允许我们将关键字去多个字段中去查询
1 | // 去 name 和 desc 两个字段查询,并将 name 字段权重提升 10 倍,name 中包括 '虚拟机' 的排在前面 |
布尔查询
布尔查询包括三种:
must: 相当于 与
should: 相当于 或
mustNot: 相当于 非
1 | // 查询 name 里不包含 虚拟机 的文档 |
布尔查询也可以支持嵌套
boolQueryBuilder1.must(boolQueryBuilder2.should(…))
排序
1 | BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); |
lt:小于
lte:小于等于
gt:大于
gte:大于等于
Elasticsearch 安全防护
目前搭建的 es 是没有任何安全认证的,也就是说只要知道了 es 的地址和端口就可以通过客户端或 head 插件来篡改、删除 es 的数据,这是不安全的,在 ES 7.x 之前,一般最多的安全防护做法是通过 nginx 转发 http 请求到 es,安全在 nginx 上做,但是这样无疑又增加了 nginx 的依赖。
X-Pack
X-Pack是Elastic Stack扩展功能,提供安全性,警报,监视,报告,机器学习和许多其他功能。 ES7.0+之后,默认情况下,当安装Elasticsearch时,会自带X-Pack,无需单独再安装。
自6.8以及7.1+版本之后,基础级安全永久免费。基础级包括了认证、授权,足够我们使用了,所以建议将 es 升级到 7.x 版本。
使用 X-Pack
在节点的 elasticsearch.yml 配置文件中添加:
1 | xpack.security.enabled: true |
加密集群节点之间的通信
证书实现加密通信的原理:TLS需要X.509证书(X.509 证书是一个数字证书,它使用 X.509 公有密钥基础设施标准将公有密钥与证书中包含的身份相关联。X.509 证书由一家名为证书颁发机构 (CA) 的可信实体颁发。CA 持有一个或多个名为 CA 证书的特殊证书,它使用这种证书来颁发 X.509 证书。只有证书颁发机构才有权访问 CA 证书)才能对与之通信的应用程序执行加密和身份验证。 为了使节点之间的通信真正安全,
必须对证书进行验证。在Elasticsearch集群中验证证书真实性的推荐方法是信任签署证书的证书颁发机构(CA)。
这样,只需要使用由同一CA签名的证书,即可自动允许该节点加入集群。
借助 bin 目录下 elasticsearch-certutil 命令生成证书
./elasticsearch-certutil ca -out config/elastic-certificates.p12 -pass “”
- elasticsearch.yml 配置节点间加密通信:
2
3
4
5
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
- 设置集群密码
借助 bin 目录下 elasticsearch-setup-passwords 设置集群密码:
2
elasticsearch-setup-passwords interactive // 自定义密码(推荐)elastic 账户是 es 的管理员账户,可以用它创建其他用户,并根据项目需要分配角色和权限。
X-Pack 如何为集群设置密码?
最简单的方法, 假定是初始部署集群阶段。
1.清空data文件(防止冲突)
2.将配置好的带证书的文件copy到另一台机器
3.根据集群配置ip、角色等信息即可
- Title: Elasticsearch 7.x 入门与实践
- Author: 薛定谔的汪
- Created at : 2019-04-10 18:01:54
- Updated at : 2023-11-17 19:37:37
- Link: https://www.zhengyk.cn/2019/04/10/elasticsearch/introduction-practice/
- License: This work is licensed under CC BY-NC-SA 4.0.