
Kafka 笔记整理

前言
前阵子做了个车联网的项目,用到了kafka,今晚回来的早,写一篇对 Kafka 的笔记整理和总结吧。
Kafka 概述
Kafka 是一个由 Scala 语言实现的开源、轻量、分布式、具有分区和副本能力的,基于 ZK 实现分布式协调的高性能,高吞吐的分布式消息订阅消息中间件。与传统的消息队列相比,Kafka 可以更好地处理活跃的流数据。可处理每秒几十万、上百万的请求,非常适用于行为跟踪、日志搜集。
Pull or Push?
Kafka 是消费者主动去获得消息(pull 模式)。
kafka 架构
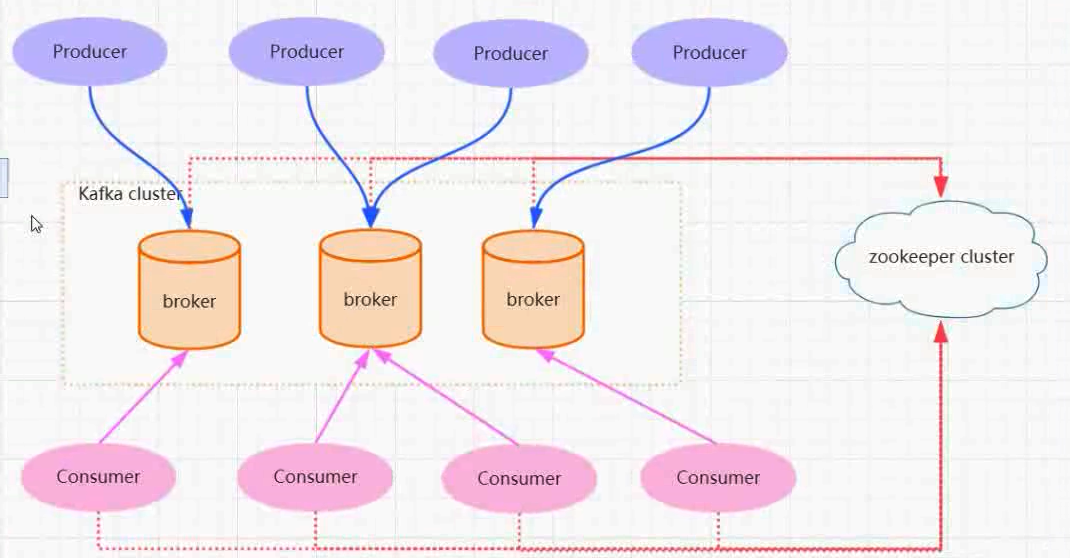
Kafka 基本概念
主题:
Kafka 将一组消息抽象成一个主题,也就是说,一个主题就是对消息的一个分类,生产者将消息发到topic,消费者通过订阅 topic 或者 topic 的某些分区进行消费。
消息:
消息 Message 是 Kafka 的基本通信单元,由固定长度的消息头和可变长度的消息体组成。
分区:
每个 Topic 可以进行分区(Partition),每个分区是一个有序队列,用于存储消息。分区在物理上对应一个文件夹,编号从0开始,依次递增,默认有 50 个分区,可配置。
分区的作用?
若没有分区,一个topic对应的消息集在分布式集群服务组中,就会分布不均匀,即可能导致某台服务器A记录当前topic的消息集很多,若此topic的消息压力很大的情况下,服务器A就可能导致压力很大,吞吐也容易导致瓶颈。
分区使得 Kafka 在并发处理上变得更加容易,理论上来说,分区越多吞吐量越高,但这要根据实际集群环境和业务场景而定。同时,分区也是 Kafka 保证消息被顺序消费以及对消息进行负载均衡的基础。
为了保证分区的均匀分布,建议创建的分区数是节点数的整数倍。
Kafka 只能保证一个分区内的消息有序性,不能保证跨分区消息的有序性,每条消息被追加到相应的分区中,是顺序写入磁盘(为什么顺序写入磁盘速度比随机写入磁盘快? ),因此效率非常高,是 Kafka 高吞吐的重要保证。
Kafka 不会立即删除已被消费的消息,也不会一直被存储,Kafka 提供了两种删除老数据的策略,一是基于消息已存储时间,二是基于分区大小,可通过配置文件配置。
副本:
每个分区可以有一到多个副本(Replica),分区的副本在集群的不同节点上,用以高可用。
副本在逻辑上抽象为 Log 对象,即分区的副本与日志对象是对应的。
Leader 副本和 Follower 副本:
每个分区可以有多个副本,这就需要保证分区多个副本之间的数据一致性,Kafka 会选举该分区的某个副本为 Leader 副本,而该分区其他副本为 Follower 副本,只有 Leader 副本才负责处理客户端的读写请求,Follower 副本从 Leader 副本同步数据(如果没有 Leader,那么所有的副本都进行读写,数据同步就太复杂、麻烦)。
Leader 和 Follower 不固定,如果 Leader 失效,会重新选举另一个 Leader。
注意:分区数可以大于节点数,副本数不能大于节点数,因为副本需要分布在不同节点上,这样才能达到备份的目的
偏移量
任何发布到分区的消息会被直接追加到日志文件(.log)的尾部,每条消息在文件内部对一个偏移量,消费者通过控制偏移量来对消息进行消费。
日志段
一个日志又被划分为一个个日志段,LogSegment,是一个逻辑概念,对应一个.log文件和两个 .index文件。
代理
Kafka 集群中每个节点可称为一个代理(Broker),每个代理具有唯一标识 id,在集群中,每增加一台代理就要为其配置i唯一标识id,
Kafka支持异步发送消息 kafka1.0以后默认支持异步发送,发送后会有一个回调
Kafka消息自动持久化,一般保存7天。
消息组的概念:
每个消费者属于特定的消费者组,每个消费者组有一个 groupId,消费者的默认消费者组是test-consumer-group,可以为消费者指定消费者组。
每个消费者有特定的唯一id,如果不指定,Kafka 会给消费者默认生成一个全局唯一 Id,消息存储到分区的算法默认是先计算出 groupId 的 hash 值,然后对分区数(默认50)进行取模得到的值就是消息要存储的目标分区。
同一个消费组内的消费者存在消息竞争关系,同一个组内的消费者消费完某条消息且 commit后不可以重复消费了,但是其他消费组内的消费者如果还未消费该消息,仍然可以继续消费。
消费者组是 Kafka 用来实现广播和单播的手段,实现消息广播要让消费者数据不同的消费者组,实现单播要让消费者属于相同的消费者组。
对比 RabbitMQ,Kafka 没有 Queue 的概念,但是通过 groupId,同样实现了 RabbitMQ 中 Queue 的作用。
AUTO_OFFSET_RESET_CONFIG 参数
对于新的 groupid:
如果设置为 earlist,那么他会从最早的消息开始消费(默认)。
如果设置为 latest,那么已经消费最大的 offset。
如果设置为 none,如果没有消息,会抛出异常。
ISR
Kafka 在 Zookeeper 中维护了 一个 ISR(In-sync Replica),保存同步的副本列表,该列表保存的是与 Leader 副本保持消息同步的所有副本所在代理的唯一标识id,如果某个 Follower 宕机,则该 Follower 代理 id 将从 ISR 中移除。
如何判断节点是否在同步状态中(Kafka 存活)?
必须满足两个条件:
- 一个存活的节点必须与 ZK 保持连接,这个主要通过 ZK 的心跳机制实现。
- 如果一个节点是 Follower 副本,那么该副本必须能及时与 Leader 副本保持消息同步,不能落后太多。
Zookeeper
ZK 负责存储 Kafka 的元数据信息,并协调 Kafka 集群。通过 ZK,可以很方便地对 Kafka 集群进行管理、水平扩展或数据迁移。
Kafka 特性
消息持久化
文件系统、磁盘存储、B树
RabbitMQ 有开启、关闭持久化的操作,Kafka 本身就是把消息顺序写入到磁盘。
高吞吐量
顺序存储,零拷贝(避免缓冲区),主题可分区
高扩展性
Zookeeper对 Kafka 进行协调管理
多客户端支持
Kafka 采用 Scala 开发,但 Kafka 支持多种语言的客户端
轻量级
消息压缩
Kafka 支持Gzip、Snappy、LZ4 三种压缩协议。通常把多条消息组成 MessageSet,然后把 MessageSet放到一条消息里面去,从而提高压缩比率进而提高吞吐量(批量发送),但是代价是降低了实时性。
Kafka 应用场景
消息队列
应用监控
网站用户行为跟踪
流处理
日志处理
Kafka 如何保证消息的可靠性传输?
消费端丢失数据
当消费者消费到消息时,默认情况下,会自动提交此消息的 offset 给 Kafka,为了保证消息的可靠性,可以设置手动提交 offset,即关闭自动提交,当消费者正常消费完后,再手动提交 offset(和 RabbitMQ 手动回执一个 ack 原理类似)。
这样可能会有消息重复消费的问题,如消费完消息后,在手动后提交 offset 之前,消费者自己挂了,那么下次还会消费此消息,所以还需要在应用层保证幂等性。
相关参数:ENABLE_AUTO_COMMIT
Kafka 数据丢失
Kafka 某个 broker 宕机,然后重新选举 partition 的 leader。此时其他的 follower 的数据还没同步完成,造成数据丢失。
可以设置如下 2 个参数:
- 给 topic 设置
replication.factor参数:这个值必须大于 1,要求每个 partition 至少 2 个副本。 - 设置
min.insync.replicas:最小 ISR,这个值必须大于 1,要求一个 leader 至少感知到有至少一个正常的 follower ,确保 leader 挂了后有一个 follower 能顶替。
生产者数据丢失
Kafka 1.0 版本以后,生产者发送消息默认是异步发送。发送成功后,会给生产者一个回调 CallBack,我们可以写一个回调函数来判断消息是否发送成功。
再配置两个参数:
- 在 producer 端设置
acks=all:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。 - 在 producer 端设置
retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是**要求一旦写入失败,就无限重试
- Title: Kafka 笔记整理
- Author: 薛定谔的汪
- Created at : 2018-11-15 18:01:54
- Updated at : 2023-11-17 19:37:37
- Link: https://www.zhengyk.cn/2018/11/15/mq/kafka/kafka-note/
- License: This work is licensed under CC BY-NC-SA 4.0.