
线程池的理解、分析

前言
前阵子看唯品会开发指南VJTools 关于多线程开发这块儿,在开发中,为了保护线程资源,建议不要自己创建线程,因为线程的创建和销毁是很耗费资源的操作,直接 new 再 start 可能会无限制新建线程,为了更好地管理、利用线程资源可以将一些线程进行池化,也就是线程池。
线程池
线程池和连接池原理类似,其核心思想就是提前准备好一些资源放到一个池子里,大家用的时候从池子中取,不用了就放回池子还可以给别人用,线程池的好处是减少在创建和销毁线程上所花的时间以及系统资源的开销,解决资源不足的问题。
Java提供了 Executors 工具类静态方法的方式来创建线程池的方式,但不推荐使用,原因详见VJTools ,其实查看其源码发现创建线程池的常用方法都是通过 new ThreadPoolExecutor(...)来实现的,可见ThreadPoolExecutor是创建线程池的核心类。
ThreadPoolExecutor
在创建线程时,直接 new ThreadPoolExecutor(...)并设置好相应参数即可。
构造方法
ThreadPoolExecutor有多个构造方法,但都是调用了同一个构造方法来完成,该构造方法用于初始化一个空的线程池:
1 | public ThreadPoolExecutor(int corePoolSize, |
corePoolSize:核心线程池的数量
maximumPoolSize:线程池最大线程数量
workQueue:工作队列
keepAliveTime:默认是非核心线程的空闲时间阈值,非核心线程空闲的时间超过这个值后会自动销毁,可通过设置allowCoreThreadTimeOut让其也控制核心线程空闲时间。
threadFactory:创建线程的工厂,默认是 DefaultThreadFactory。
handler:拒绝策略,当请求的线程过多时,连线程池都满了,再有新的请求过来时执行的策略,默认是不处理请求并抛出异常。
怎样来理解这几个概念呢?知乎上某位大佬举的例子就很好,有这么一家给客户提供 XX业务的公司(ThreadPool),平时有自己的员工干活(corePoolSize),当业务量不大时这些员工能应付得来,当业务稍微多时,原来的员工手头都有工作,不能立即接手新的,那后来的业务就要搁置下(workQueue),等手头忙完再做,随着业务量的增大,搁置的业务也太多了,自己人手又不够只能把活给外包人员来做,因为公司能力有限不能无限制的招外包人员,当公司成员达到最大后(maximumPoolSize),再有新的业务来就拒绝不处理了(handler),当外包人员有段时间(keepAliveTime)不干活,公司就辞退这些外包人员,如果自己员工也有段时间不干活,甚至可以辞退自己的员工(allowCoreThreadTimeOut);
核心属性
线程池的状态
1 | // runState is stored in the high-order bits |
查看源码注释:
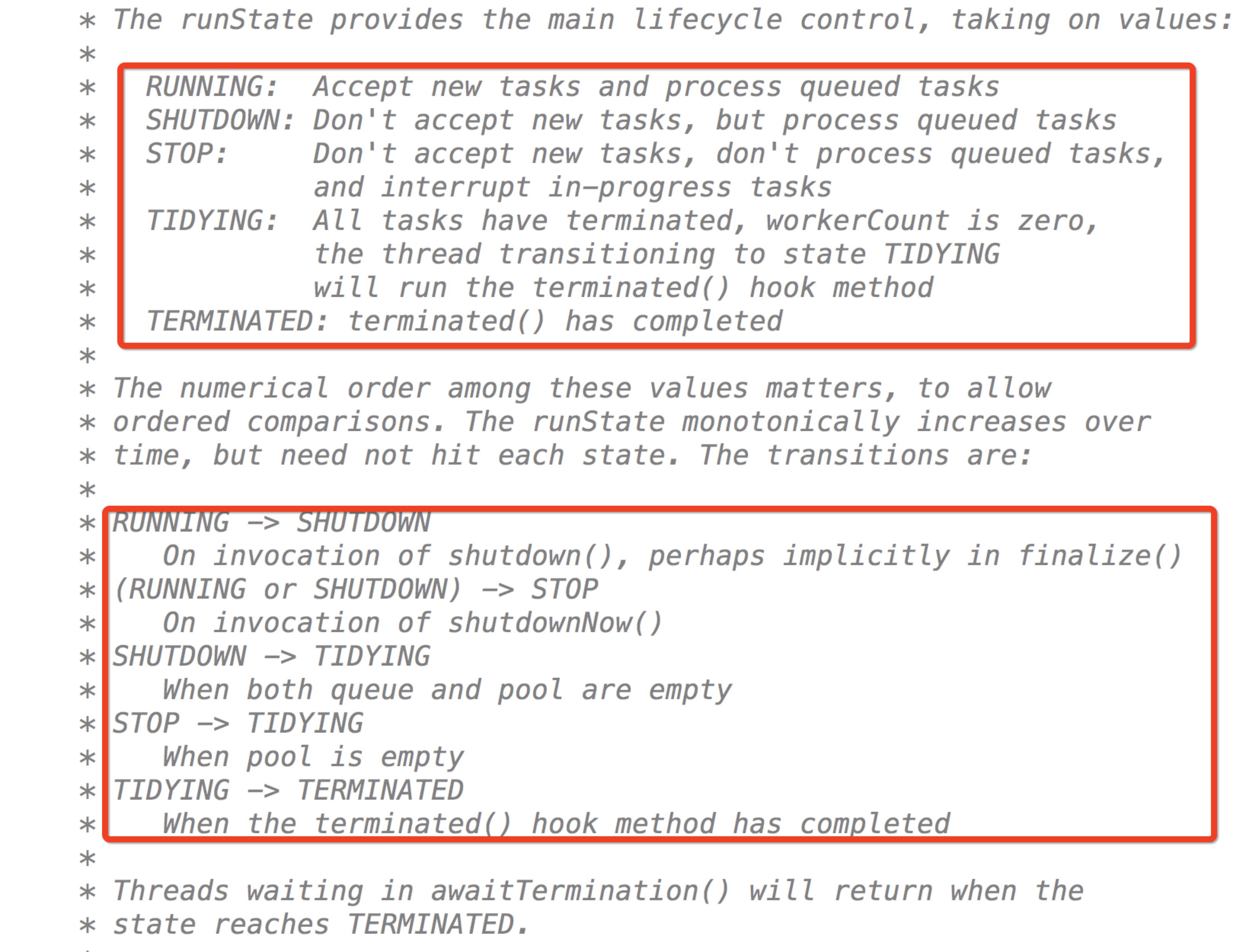
通过注释可知:
RUNNING:线程池运行状态,可接受新任务并处理排队任务
SHUTDOWN:不接受新任务,但队列里的任务要执行完毕,调用shutdown()方法后的状态。
STOP:调用 shutdownNow()方法后的状态,不接受新任务,不执行队列里任务而是将其打断。
TIDYING:我的理解这是一个过渡状态,所有任务都执行完毕时,在线程池终止前会变为此状态。每次执行 shutdwon()和 shutdownNow()都会做相应判断是否更新为此状态。
TERMINATED:线程池终止状态,执行
terminated()后。
我画了个线程池状态转换图:
![]()
其他属性
1 | /** |
核心方法
void execute(Runnable command)方法表示让线程池执行一个任务,还有个方法是 submit(…)方法,其实 submit 方法里还是调用了 execute 方法,不同的是 submit 方法在ThreadPoolExecutor的父类AbstractExecutorService中,该方法可以返回一个 Future 对象,通过 Future 可以判断该线程是否执行完毕。
1 | public <T> Future<T> submit(Callable<T> task) { |
注意:使用submit()时,假如任务中抛了异常,异常信息默认是被内部捕获、不打印,但使用 execute()可以打印异常信息。
示例:
1 | public class ThreadPoolExecutorTest { |
void execute(Runnable command)
分析其源码:
1 | public void execute(Runnable command) { |
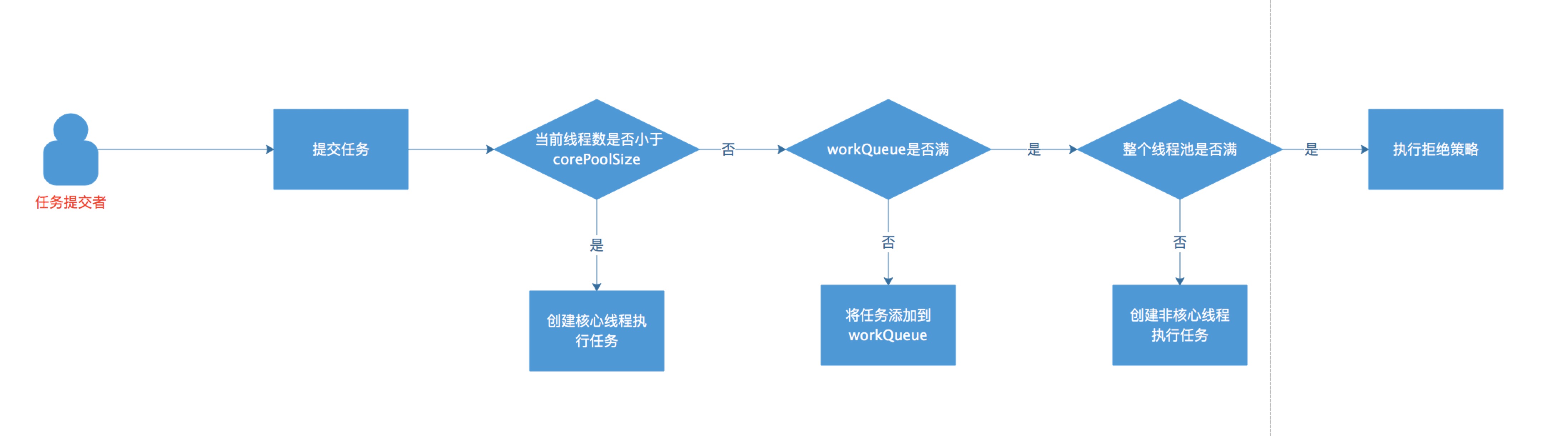
execute 方法流程图:
beforeExecute和afterExecute
ThreadPoolExecutor 提供了两个空函数,我们可以自定义线程池继承 ThreadPoolExecutor,重写这两个函数实现在执行execute方法前后做的工作。
ThreadPoolExecutor总结
关键是要理解 ThreadPoolExecutor 的构造方法中各个参数的概念和用途,并根据实际场景设置合理的参数来创建线程池。
线程池的底层存储结构是 HashSet,每个工作线程被包装成 Worker 存储在 HashSet 中。
workQueue 是一个阻塞队列,当提交任务时,判断顺序:先判断核心线程数量,再判断 workQueue 是否满,最后判断整个线程池是否满。
使用了 ReentrantLock 锁保证了线程的安全性。
SpringBoot 中使用线程池
SpringBoot 中使用ThreadPoolTaskExecutor作为线程池的实现,并且配置了相应注解来简化线程池的使用
1 |
|
创建了两个线程池,executorSecond和executorFirst
使用某个线程池时,我们只需要在 service 的方法上添加@Async("executorFirst")或@Async("executorSecond")注解,指定该方法具体使用哪个线程池,这具有线程池隔离的作用。
- Title: 线程池的理解、分析
- Author: 薛定谔的汪
- Created at : 2018-08-31 18:01:54
- Updated at : 2023-11-17 19:37:37
- Link: https://www.zhengyk.cn/2018/08/31/java/ThreadPool/
- License: This work is licensed under CC BY-NC-SA 4.0.