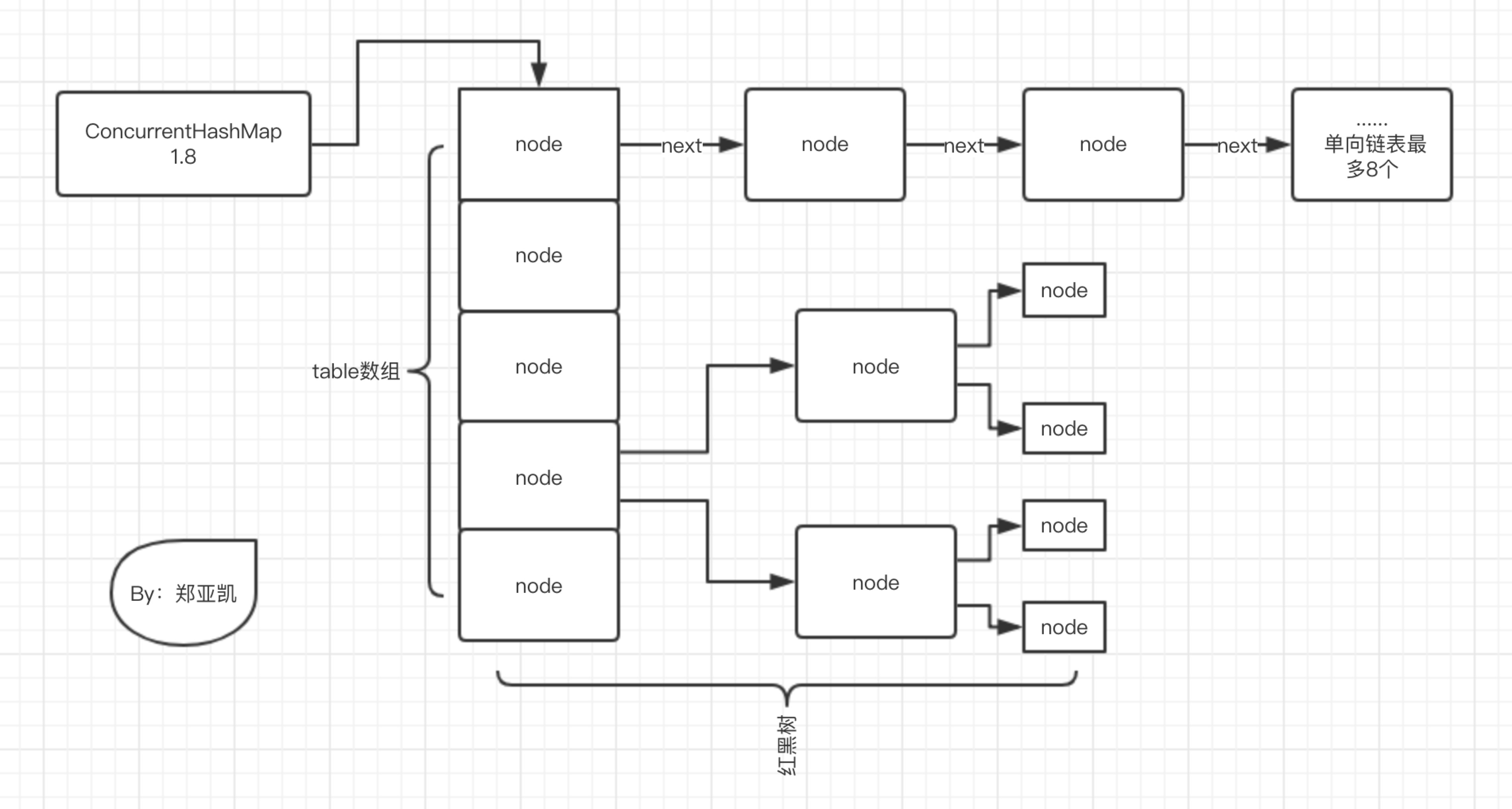
//onlyIfAbsent 当key已存在,true-不改变value的值 false-更新value final V putVal(K key, V value, boolean onlyIfAbsent) { //ConcurrentHashMap 的 key 和 value 都不能为空 if (key == null || value == null) thrownewNullPointerException(); //计算 hash inthash= spread(key.hashCode()); intbinCount=0; //自旋 for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0) //当数组为空时初始化table tab = initTable(); //根据hash 计算 key 的索引i,CAS 设置索引i上的值,如果i 位置处没有元素,则直接添加不用加锁 elseif ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, newNode<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } //如果插入时,索引i上的 Node 正好是ForwardingNode,那ForwardingNode就给人家让位置,自己再找新的位置 elseif ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { //到这里就表示原来索引i 处有节点,hash冲突了,hash 冲突先转链表,当链表长度超过8时转红黑树 VoldVal=null; //这里使用synchronized保证同步,锁是索引i处的 Node synchronized (f) { //再校验一次,防止期间索引i处的node被修改过 if (tabAt(tab, i) == f) { //排除ForwardingNode和 TreeBin if (fh >= 0) { binCount = 1; //自旋 for (Node<K,V> e = f;; ++binCount) { K ek; //key 相同,覆盖value if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } //key 不相同,构造新 Node 插入链表 Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = newNode<K,V>(hash, key, value, null); break; } } } //如果索引i处已经是红黑树了,则构建新 Node 插入红黑树 elseif (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) //单向链表转红黑树,期间涉及到扩容 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); returnnull; }
思考:为什么HashMap 中可以存null,但是ConcurrentHashMap 不可以呢?
我的理解是ConcurrentHashMap是并发的,在 get 的过程中可能有其他线程把目标元素给移除了,我们调用 get 得到的 value是 null,但是我们不知道这个null是具体存 value 的时候存的就是 null 还是没获取到 value 返回的null,再就是在并发情况下调用contains(key)和 get(key) 后的结果不是我们想要的了,为了避免歧义所以ConcurrentHashMap 不允许存 null。
/** * Returns the number of mappings. This method should be used * instead of {@link #size} because a ConcurrentHashMap may * contain more mappings than can be represented as an int. The * value returned is an estimate; the actual count may differ if * there are concurrent insertions or removals. * * @return the number of mappings * @since 1.8 */ publiclongmappingCount() { longn= sumCount(); return (n < 0L) ? 0L : n; // ignore transient negative values }