
Zookeeper笔记整理

前言
本文总结下 Zookeeper 中的一些知识点,便于自己查漏补缺,本篇当做一个笔记来写,所以写的有点乱。
Zookeeper 总结
Zookeeper是一个分布式应用协调服务, Dubbo推荐使用它来当做注册中心,kafka 集群也需要它来协调各个节点。 Zookeeper 是基于key-value的文件目录式存储,当有服务注册时,会创建一个节点,每一个节点对应一个 value。
ZK节点
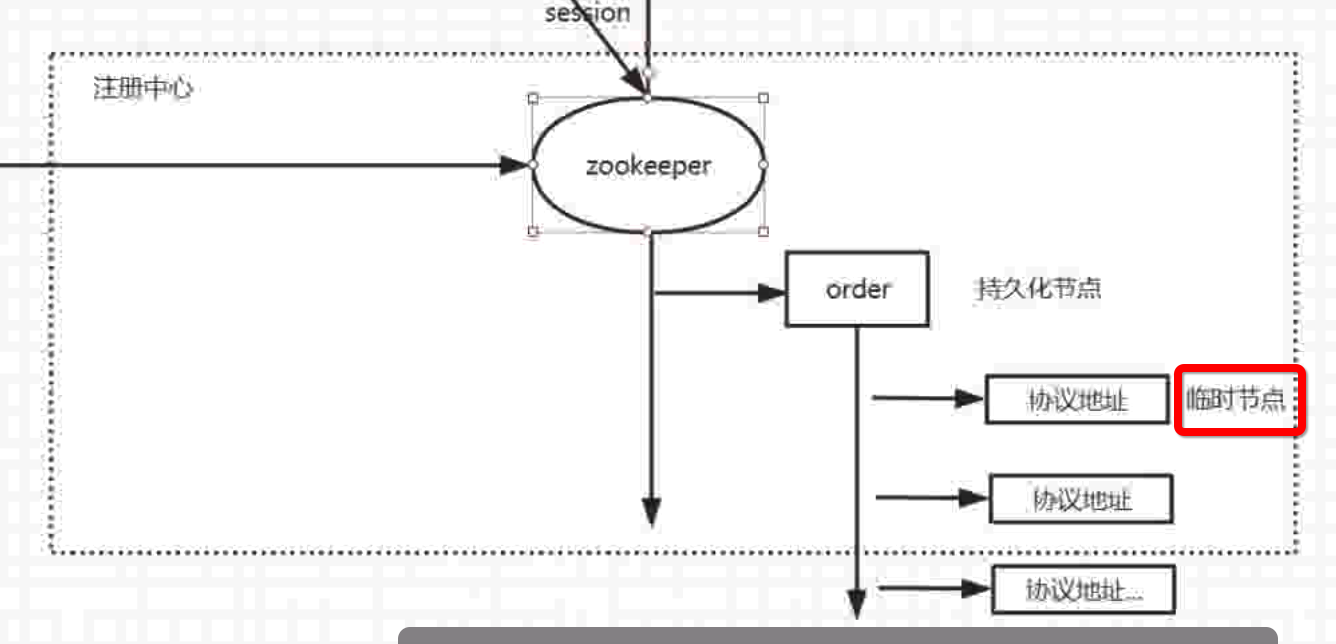
ZK中的节点可分为持久节点和临时节点
持久节点
创建后不会自动删除,zk 命令:create /order 0 ,标识在”/“根目录下创建一个 order 节点,值是0。
临时节点
临时节点,生命周期存在与客户端和zk服务端一次会话中,会话结束后自动删除。ZK的临时节点实现了服务的上下线感知功能。如下图示例:dubbo的order服务注册到zk上的节点信息是服务的协议地址,他们就是临时节点。
使用 create -e key value 创建临时节点
ZK 节点的一些特性
同级节点的唯一性,这和操作系统统一目录下不能有重名一个道理。
节点的有序性,在创建节点时,使用create -s key value, -s 标识sequence
临时节点不能有子节点。
zoo.cfg
下载ZK 解压后,在其 conf 目录下有一个 zoo.sample.cfg文件,zk启动会加载 zoo.cfg文件,所以复制一份重新命名为zoo.cfg即可,zoo.cfg中有几个属性需要总结下:
tricktime=2000:时间单位 默认2000 即 2秒为一个时间单位
initLimit=10:最大的初始化同步时间 10个tricktime 即默认20秒
syncLimit=5: Leader 和 Folllower之间的最大心跳检测时间(ZAB协议会给 zk 集群选举一个 leader,其他的节点为follower,leader 可做读写,follower只能读,区别于 kafka 中分区副本的leader和flowder)
dataDir:持久化节点和事务日志等数据存储位置。默认/tmp/zookeeper下,建议修改到其他位置
节点详细信息
使用ZkClient客户端登录 zk,使用 get /order查看先前创建的节点信息:
1 | cZxid = 0x28 //创建节点时事务 id |
ZK集群中的角色
Leader: 可读可写,处理事务请求
Follower:同步 Leader,只读
Observer:监控 zk 集群,不参与选举。
leader的选举机制
zk 集群中的所有节点都会并发创建自己的znode,每个znode是唯一不重复的,value 最小的就是 leader,leader 挂了后,再从其余节点继续选择value 最小的为新 leader。(和分布式锁原理差不多)
Zookeeper集群节点数量为什么要是奇数个?
Zookeeper集群容错是指,当宕掉几个 ZK 服务器之后,剩下的个数必须大于宕掉的个数,也就是剩下的服务数必须大于n/2,集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。所以为了节约资源,集群中部署基数台机器即可。
Zookeeper脑裂(Split-Brain)问题
什么是 ZK 的脑裂?
假如集群中有三个节点,一主两从,当主挂掉后,两个从节点通信正常的情况下可以达成共识,从中再选举一个为主,但当两个从节点通信故障,这时双方都认为自己应该应该选为 Leader,这样集群中就出现了两个主节点。
解决脑裂问题的方式?
- Quorums,法定人数,集群中超过半数投票认为 master 挂掉后才能选举Leader。
- Redundant communications,冗余通信,集群中采用多种通信方式,防止一种协议失效。
- Fencing,共享资源的方式,设置一个共享资源,谁能看到这个共享资源,谁就在集群中,谁能获得此共享资源,谁就是 Leader
ZK 是如何解决脑裂的?
ZK 采用 Quorums 方式的方式。
会话状态
未连接—>连接中–>已连接–>关闭
Not_Connected–>Connecting–>Connected–>Closed
连接失败直接关闭
Watch 事件机制
zk 节点信息变更时,可以通过 wacth 机制告诉所有的客户端,客户端可以据此来更细自己本地的节点缓存信息。
数据存储
使用DataTree ConcurrentHashMap 存储节点信息
事务日志:zoo.cfg的dataDir
快照日志:zoo.cfg的dataDir
运行日志:/bin/zookeeper.out
基于 Java API
ZK 原生Java API操作复杂,推荐使用高度封装的Curator。
Zookeeper应用
注册中心、配置中心,分布式协调服务(kafka 集群),分布式锁等等。
基于 ZK 的分布式锁
方案一:
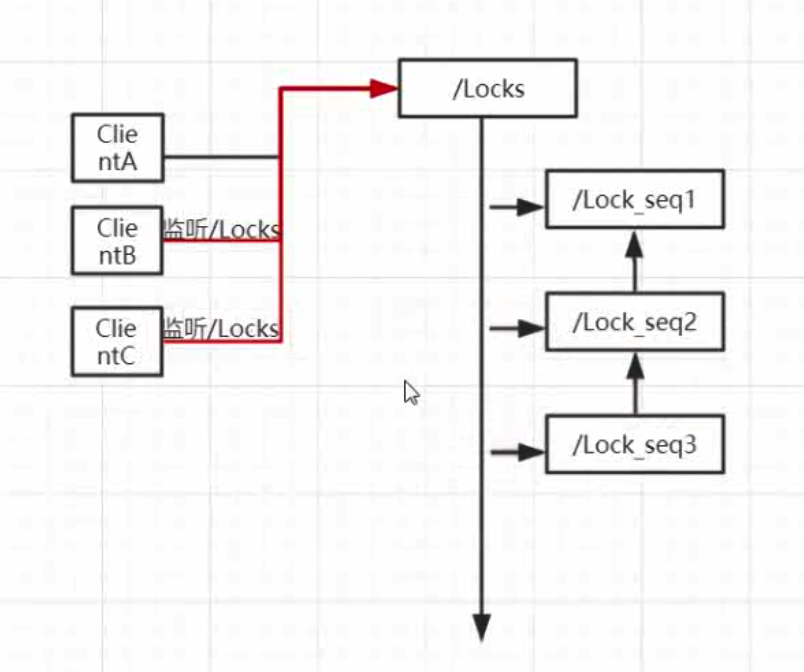
利用 znode 在同一目录下的唯一性,同一时刻所有的客户端都去创建/Locks/lock 节点,但最终只有一个能创建成功,创建成功的则获得锁;获得锁的客户端释放锁时,将节点 Lock 删除,这时ZK 的 Watch 机制告诉其他所有的客户端 Lock 节点已删除,这样其他的节点再次去竞争创建 Lock 节点进而获得锁,如图所示:

缺点: 羊群效应。当客户端很多的时候,每次都要通知所有的客户端去竞争创建节点,对资源消耗很大,不推荐使用此方案。
方案二:
创建有序节点,所有的客户端都可以创建临时节点znode,znode的 value从小到大排序,谁的 value 最小,谁就获得锁,同时其他未获得锁的节点监听前一个比自己小的节点,当释放锁时,当前代表获取锁的临时节点删除,这样一直监听它的节点就会收到删除事件,然后它再判断当前目录下自己是不是最小的节点,如果是那么获取锁,如果不是则继续监听等待,直到获取锁。
ZK实现分布式锁代码推荐使用 curator 来实现,也可以参照 ReentrantLock 原理实现可重入锁。
为什么SpringCloud 更推荐使用 ZK做注册中心
这两天看小马哥直播中谈到了 SpringCloud 推荐使用 ZK 来做注册中心,并且谈到了Eureka、ZK、Consul 的对比,以及为何推荐使用 ZK,这里记录总结下。
各注册中心的对比
| 比较点 | Eureka | ZK | Consul |
|---|---|---|---|
| 熟悉度 | 相对陌生 | 比较熟悉 | 更陌生 |
| CAP | AP(最终一致性) | CP | AP(最终一致性) |
| 一致性方式 | Http 轮询 | ZAB | RAFT |
| 通信方式 | HTTP REST | 自定义协议 | HTTP REST |
| 更新机制 | Peer to Peer(服务端之间)、定时轮询(客户端与服务端) | Watch | Agent监听 |
| 适用规模 | 20k-30k 之间的实例数 | 10k-20k | <3k,超过3k 后,列表更新缓慢 |
这个是技术专家小马哥给的数据,也是经过很多实战经历总结出的经验,综合以上对比,在绝大多数项目中使用 ZK 是最合适的,再就是使用 Eureka 注册中心的话,如果项目中再用到了配置中心,还需要额外部署如 Spring Cloud Config,再次增加学习运营成本。而 ZK 不仅可以做注册中心,还可以做配置中心,大大减少了项目成员的开发和运维难度。
- Title: Zookeeper笔记整理
- Author: 薛定谔的汪
- Created at : 2018-04-01 18:01:54
- Updated at : 2023-11-17 19:37:36
- Link: https://www.zhengyk.cn/2018/04/01/zk/zookeeper/
- License: This work is licensed under CC BY-NC-SA 4.0.